Softwarearchitektur ist das Fundament jeder effizienten Softwarelösung. Sie ist der Blaupause gleich, die den Rahmen für Systemstrukturen, Regeln und Prozesse setzt, und dabei hilft, eine robuste und skalierbare Softwarelösung zu schaffen. In einer Welt, die zunehmend von technologischen Innovationen angetrieben wird, ist eine gut durchdachte Softwarearchitektur entscheidend für den Erfolg eines jeden Softwareprojekts.
Einführung in die Softwarearchitektur: Warum sie für erfolgreiche Projekte entscheidend ist
Das Verständnis der Architektur ist entscheidend, um die Komplexität moderner Softwaresysteme zu navigieren und erfolgreiche Lösungen zu liefern.
Die Monolithische Softwarearchitektur: Ein Umfassender Überblick
Ein tiefgehender Einblick in die monolithische Softwarearchitektur, illustriert durch realitätsnahe Beispiele wie Shopify und WordPress, und stellt einen Vergleich mit modernen Mikroservice-Architekturen an.
Monolith mit serviceorientierter Architektur (SOA): Die Kunst der Integration
Entdecken Sie die Zukunft der Softwarearchitektur: Die Vereinigung von Monolith und SOA. Erfahren Sie, wie diese Fusion die Entwicklungslandschaft neu gestaltet.
Die monolithische Softwarearchitektur, ein traditionelles Modell für die Entwicklung von Softwareanwendungen, integriert alle Komponenten innerhalb einer einzigen Codebasis. Dieses Architekturmodell hat seine Wurzeln in den Anfängen der Softwareentwicklung und steht im Kontrast zu moderneren Ansätzen wie den Mikroservices.
Definition und Kernkonzepte
In der monolithischen Architektur werden alle Funktionen und Dienste innerhalb einer einzigen Codebasis integriert. Die internen Komponenten wie Datenbankzugriff, Geschäftslogik und Benutzeroberflächen sind eng miteinander verknüpft und interagieren innerhalb der monolithischen Struktur.
Beispiele für monolithische Architekturen
Traditionelle Content-Management-Systeme (CMS) wie WordPress sind typische Beispiele für monolithische Architekturen.
Shopify nutzt eine modulare monolithische Architektur, die als eine verbesserte Form der monolithischen Architektur angesehen wird und es ermöglicht, gut definierte Modulgrenzen und ein hohes Maß an Parallelität zu erreichen.
Vergleich mit anderen Architekturansätzen
Die monolithische Architektur wird oft mit der Mikroservice-Architektur verglichen. Während monolithische Anwendungen als eine einzige komplette Einheit erstellt werden, besteht die Mikroservice-Architektur aus einer Sammlung kleinerer, unabhängig einsetzbarer Dienste. Die Wahl zwischen diesen Architekturen hängt von verschiedenen Faktoren ab, einschließlich der Projektgröße und -anforderungen.
Vorteile und Nachteile der monolithischen Architektur
Pro:
Einfachheit in der Entwicklung und dem Deployment: Durch die Integration aller Komponenten in einer einzigen Codebasis sind die Entwicklung und das Deployment einfacher und geradliniger.
Einheitliches Entwicklungsmodell: Die Verwaltung und Wartung sind erleichtert, da alle Komponenten eng miteinander verknüpft sind.
Effizienz in Bezug auf Performance: Durch die enge Kopplung der Komponenten kann die Leistung verbessert werden.
Contra:
Mangel an Flexibilität: Änderungen oder neue Funktionen können schwer zu implementieren sein, da die gesamte Anwendung neu kompiliert und deployt werden muss.
Schwierigkeiten bei der Skalierung und Anpassung an wachsende Anforderungen: Insbesondere wenn das Projekt wächst und sich die Anforderungen weiterentwickeln, kann es erforderlich sein, auf eine skalierbarere und flexiblere Architektur umzusteigen.
Potentielle Herausforderungen bei der Fehlerbehebung und der Isolierung von Problemen: Probleme können schwer zu isolieren und zu beheben sein, da Fehler sich durch die gesamte Anwendung ausbreiten können.
Fazit
Die Wahl zwischen monolithischer und anderen Softwarearchitekturen hängt von den spezifischen Anforderungen eines Projekts ab. Monolithische Architekturen bieten Einfachheit und Effizienz, während Mikroservices und modulare Ansätze Flexibilität und Skalierbarkeit bieten. Die Überlegung und Abwägung der Vor- und Nachteile ist entscheidend für den Erfolg eines Softwareprojekts.
Die Softwareentwicklung ist ein komplexes Gebiet, das ständig wächst und sich verändert. Eines bleibt jedoch konstant: Die Bedeutung einer soliden Softwarearchitektur. Dieser Artikel wirft einen Blick auf die Grundlagen der Softwarearchitektur, den Unterschied zwischen Architektur und Design und erklärt, warum eine gute Architektur für erfolgreiche Softwareprojekte unerlässlich ist. Anhand konkreter Beispiele aus der Wirtschaft werden diese Konzepte veranschaulicht.
Was ist Softwarearchitektur?
Softwarearchitektur bezieht sich auf die Struktur eines Systems, die aus verschiedenen Elementen, ihren Beziehungen zueinander und den Eigenschaften beider besteht. Es handelt sich um eine Blaupause für ein System, die es Entwicklern ermöglicht, Software effizient und in einer strukturierten Weise zu erstellen.
Beispiel: Wenn wir an Gebäude denken, stellt die Architektur den Gesamtplan dar, während das Design die ästhetischen Merkmale betrifft. Bei einem Unternehmen wie Apple zeigt die Architektur des iOS-Betriebssystems, wie die verschiedenen Komponenten zusammenarbeiten, während das Design beeinflusst, wie Benutzeroberflächen oder Apps aussehen.
Unterschied zwischen Softwarearchitektur und Software-Design
Es kann leicht zu Verwirrung kommen, wenn man versucht, zwischen Architektur und Design zu unterscheiden. Kurz gesagt:
Softwarearchitektur ist der hochrangige strukturelle Rahmen, der die wichtigsten Elemente und Beziehungen in einem System definiert.
Software-Design hingegen befasst sich mit den Details. Es bestimmt, wie die in der Architektur definierten Komponenten in die Praxis umgesetzt werden.
Beispiel: Nehmen wir Netflix als Beispiel. Die Softwarearchitektur von Netflix könnte sich darauf konzentrieren, wie sie Streaming-Dienste global anbieten, Daten speichern und Nutzerverhalten analysieren. Das Design hingegen könnte sich darauf konzentrieren, wie Benutzer durch die App navigieren oder wie Videos effizient gestreamt werden.
Warum ist eine gute Architektur entscheidend für erfolgreiche Projekte?
Skalierbarkeit: Eine robuste Architektur ermöglicht es, ein System problemlos zu erweitern. Mit der wachsenden Anzahl von Benutzern und Daten muss eine Software skalieren können, ohne dass es zu Performance-Problemen kommt.
Beispiel: Amazon musste seine ursprüngliche Architektur überdenken, um dem rasanten Wachstum des Online-Handels gerecht zu werden. Durch die Umstellung auf eine Microservices-Architektur konnte Amazon sein Angebot problemlos erweitern und neue Dienste hinzufügen, ohne bestehende Systeme zu beeinträchtigen.
Wartbarkeit: Ein gut durchdachter architektonischer Ansatz erleichtert das Auffinden und Beheben von Fehlern und das Hinzufügen neuer Funktionen.
Beispiel: Microsoft hat im Laufe der Jahre mehrere Versionen seines Betriebssystems Windows herausgebracht. Dank einer konsistenten Architektur konnte das Unternehmen Funktionen hinzufügen und Fehler beheben, ohne das gesamte System neu schreiben zu müssen.
Performance: Ein effizientes Architekturmodell stellt sicher, dass Ressourcen optimal genutzt werden und Nutzeranfragen schnell bearbeitet werden.
Beispiel: Google muss Milliarden von Suchanfragen pro Tag verarbeiten. Eine leistungsstarke Architektur sorgt dafür, dass diese Anfragen in Sekundenschnelle bearbeitet werden.
Sicherheit: In einer gut konzipierten Architektur werden sicherheitsrelevante Aspekte von Anfang an berücksichtigt.
Beispiel: Banken wie die Deutsche Bank müssen sicherstellen, dass ihre Systeme gegen Hackerangriffe geschützt sind. Eine solide Architektur stellt sicher, dass Daten sicher gespeichert und übertragen werden.
Abschluss
Die Softwarearchitektur ist weit mehr als nur ein Plan oder eine Skizze; sie ist das Fundament, auf dem erfolgreiche Softwareprojekte aufgebaut werden. Sie beeinflusst Skalierbarkeit, Wartbarkeit, Performance und Sicherheit – alles entscheidende Faktoren für den Erfolg eines Projekts. Unternehmen wie Apple, Netflix, Amazon, Microsoft und die Deutsche Bank haben erkannt, wie wichtig eine solide Architektur für ihre Geschäftserfolge ist. Jeder, der in der Softwareentwicklung tätig ist oder plant, sich diesem Bereich zuzuwenden, sollte die Bedeutung der Architektur nicht unterschätzen.
In der Welt der Softwareentwicklung hat die Wahl der richtigen Architektur einen erheblichen Einfluss auf den Erfolg eines Projekts. Eine der interessantesten und gleichzeitig kontrovers diskutierten Architekturansätze ist die Kombination aus einem Monolithen und der serviceorientierten Architektur (SOA). Dieser Ansatz ermöglicht es Entwicklern, die Vorteile einer monolithischen Struktur mit der Flexibilität und Skalierbarkeit von SOA zu kombinieren. In diesem Blog-Post werden wir uns eingehend mit dieser Architektur auseinandersetzen, ihre Vor- und Nachteile beleuchten und praktische Umsetzungstipps geben.
Der Monolith: Ein Überblick
Bevor wir uns in die Tiefe begeben, werfen wir einen Blick auf das, was ein Monolith in der Softwarearchitektur ist. Ein Monolith ist im Wesentlichen eine einzige, umfangreiche Anwendungseinheit, in der alle Komponenten und Funktionen zusammengefasst sind. Alle Teile der Anwendung teilen denselben Code und dieselbe Datenbank. Monolithen sind oft einfach zu entwickeln, zu testen und zu deployen, was sie zu einer attraktiven Wahl für kleine bis mittelgroße Projekte macht.
Die serviceorientierte Architektur (SOA): Ein Überblick
Auf der anderen Seite haben wir die serviceorientierte Architektur (SOA), die auf der Idee basiert, dass Anwendungen als lose gekoppelte Dienste entwickelt werden sollten, die über APIs miteinander kommunizieren. Jeder Dienst erfüllt eine bestimmte Aufgabe und kann unabhängig entwickelt, getestet und skaliert werden. SOA bietet Skalierbarkeit, Flexibilität und Wiederverwendbarkeit von Komponenten.
Die Fusion: Monolith mit SOA
Die Idee hinter dem Monolith mit SOA-Ansatz ist, die Vorteile beider Welten zu nutzen. Anstatt eine monolithische Anwendung in kleinere, voneinander unabhängige Dienste aufzuteilen, werden die internen Komponenten eines Monolithen als Dienste modelliert und über API-Schnittstellen miteinander verbunden.
Vorteile
Graduelle Migration: Bestehende monolithische Anwendungen können schrittweise in eine SOA umgewandelt werden, wodurch der Aufwand und das Risiko reduziert werden.
Flexibilität: Durch die Aufteilung interner Komponenten in Dienste können Entwickler einzelne Teile der Anwendung unabhängig entwickeln, testen und aktualisieren, ohne den gesamten Monolithen zu beeinflussen.
Wiederverwendung: Dienste können in verschiedenen Teilen der Anwendung wiederverwendet werden, was zu einer verbesserten Code-Effizienz führt.
Skalierbarkeit: Die Möglichkeit, einzelne Dienste zu skalieren, ermöglicht eine effizientere Ressourcennutzung und eine bessere Skalierungsfähigkeit.
Herausforderungen
Komplexität: Die Integration von SOA in einen Monolithen kann die Gesamtkomplexität des Systems erhöhen.
Datenkonsistenz: Da Daten in einem Monolithen zentralisiert sind, kann die Verwaltung der Datenkonsistenz zwischen den Diensten kompliziert sein.
Abhängigkeiten: Die Dienste müssen sorgfältig entkoppelt und gepflegt werden, um Abhängigkeitsprobleme zu vermeiden.
Praktische Umsetzung
Die Umsetzung eines Monoliths mit SOA erfordert eine gründliche Planung und eine klare Vorstellung davon, wie die internen Komponenten des Monolithen in Dienste aufgeteilt werden können. Hier sind einige bewährte Praktiken:
Identifizierung von Diensten: Identifizieren Sie die internen Komponenten des Monolithen, die als Dienste modelliert werden können. Denken Sie darüber nach, wie diese Dienste miteinander interagieren.
API-Design: Entwickeln Sie klare und gut dokumentierte API-Schnittstellen für jeden Dienst. Dies ist entscheidend, um eine reibungslose Kommunikation zwischen den Diensten zu gewährleisten.
Datenmanagement: Stellen Sie sicher, dass Sie eine effektive Strategie für das Datenmanagement haben. Dies kann die Verwendung von Datenbanken pro Dienst oder die Implementierung eines zentralen Datenzugriffsdienstes umfassen.
Monitoring und Debugging: Implementieren Sie umfassende Überwachungs- und Debugging-Tools, um die Leistung und Zuverlässigkeit der Dienste sicherzustellen.
Sicherheit: Denken Sie an die Sicherheit und die Berechtigungssteuerung für den Zugriff auf Dienste und Daten.
Fazit
Die Kombination eines Monolithen mit der serviceorientierten Architektur (SOA) kann eine effektive Möglichkeit sein, die Flexibilität und Skalierbarkeit von SOA in eine bestehende monolithische Anwendung zu integrieren. Dieser Ansatz erfordert sorgfältige Planung und eine klare Vorstellung davon, wie die internen Komponenten des Monolithen in Dienste aufgeteilt werden können. Mit den richtigen Praktiken und Werkzeugen kann jedoch ein Monolith mit SOA die Entwicklung und Wartung komplexer Anwendungen erheblich erleichtern.
In der Softwareentwicklung gibt es selten eine „One-Size-Fits-All“-Lösung, und die Wahl zwischen verschiedenen Architekturansätzen hängt von den spezifischen Anforderungen und Zielen eines Projekts ab. Ein Monolith mit SOA ist eine interessante Option, die in Betracht gezogen werden sollte, wenn Sie die Vorteile beider Architekturen nutzen möchten.
In der schnelllebigen Welt der Technologie ist die Rolle eines Tech-Leads komplex und vielschichtig. Neben technischem Know-how sind Führungsqualitäten und die Fähigkeit zur Selbstreflexion entscheidend. Ein Tech-Lead-Tagebuch kann hierbei ein wertvolles Instrument sein. In diesem Artikel werden wir die Schlüsselelemente eines solchen Tagebuchs und dessen Nutzen erörtern.
Rollen und Verantwortlichkeiten eines Tech-Leads
Was gehört ins Tagebuch?
Ein Tech-Lead ist nicht nur ein technischer Experte, sondern auch ein Mentor, Projektmanager und Teamleiter. Daher sollte das Tagebuch folgende Aspekte abdecken:
Technische Entscheidungen: Welche Architekturentscheidungen wurden getroffen? Warum?
Projektmanagement: Welche Meilensteine wurden erreicht? Welche stehen noch aus?
Teaminteraktion: Wie ist die aktuelle Teamdynamik? Gibt es Konflikte oder besondere Erfolge?
Tagebuch-Tipp
Nutzen Sie Vorlagen für wiederkehrende Aufgaben und Checklisten, um den Überblick zu behalten.
Teamdynamik verstehen und managen
Warum ist das wichtig?
Ein Tech-Lead muss nicht nur technische, sondern auch menschliche Probleme lösen. Ein Tagebuch kann Aufschluss darüber geben, wie Teammitglieder interagieren, wo es Reibungspunkte gibt und wie diese gelöst werden können.
Tagebuch-Tipp
Führen Sie wöchentliche Reflexionen durch, um die Teamdynamik zu bewerten und festzustellen, wo Verbesserungen möglich sind.
Persönliche Entwicklung
Selbstreflexion als Schlüssel zum Erfolg
Ein Tech-Lead sollte auch die eigene Entwicklung im Blick haben. Das Tagebuch ist ein Ort für:
Selbstreflexion: Was haben Sie diese Woche gelernt? Wo könnten Sie sich verbessern?
Zielsetzung: Welche kurz- und langfristigen Ziele haben Sie?
Work-Life-Balance: Wie gestaltet sich die Balance zwischen Beruf und Privatleben?
Tagebuch-Tipp
Setzen Sie sich regelmäßig Zeit für die Selbstreflexion und Zielüberprüfung. Nutzen Sie das Tagebuch als einen „sicheren Raum“ für ehrliche Selbstbewertung.
Fazit
Ein Tech-Lead-Tagebuch ist mehr als nur ein Notizbuch; es ist ein Instrument für effektive Führung und Selbstreflexion. Durch die Dokumentation von technischen Entscheidungen, Teamdynamiken und persönlichen Entwicklungen bietet es wertvolle Einblicke, die zur kontinuierlichen Verbesserung beitragen können.
Die „Boy Scout Rule“ (BSR) ist ein ethisches Prinzip, das besagt: „Hinterlasse den Campingplatz sauberer, als du ihn vorgefunden hast.“ In der Softwareentwicklung bedeutet dies, den Code immer ein wenig besser zu hinterlassen, als man ihn vorgefunden hat. Dieser Artikel richtet sich an Intermediate Developer, die sich zu Senior Developer weiterentwickeln und ihre Fähigkeiten verbessern möchten.
Was ist die Boy Scout Rule?
Die Boy Scout Rule ist ein ethisches Prinzip, das besagt, dass man immer einen kleinen Beitrag zur Verbesserung des Codes leisten sollte, den man bearbeitet. Die Idee ist, dass viele kleine Verbesserungen im Laufe der Zeit zu einem deutlich besseren Codebase führen können.
Warum ist die Boy Scout Rule wichtig?
Code-Qualität
Die Anwendung der Boy Scout Rule führt zu einer kontinuierlichen Verbesserung der Code-Qualität. Dies ist besonders wichtig in agilen Entwicklungsumgebungen, wo der Code ständig geändert wird.
Teamdynamik
Die Boy Scout Rule fördert eine Kultur der Verantwortung und des Respekts innerhalb des Entwicklungsteams. Wenn jeder Entwickler sich bemüht, den Code zu verbessern, wird die Teamdynamik positiv beeinflusst.
Wie implementiert man die Boy Scout Rule?
Code Reviews
Nutzen Sie Code Reviews als Gelegenheit, um die Boy Scout Rule anzuwenden. Wenn Sie auf einen Abschnitt mit schlecht geschriebenem Code stoßen, verbessern Sie ihn.
Refactoring
Refactoring ist der Prozess der Änderung eines Software-Systems, ohne sein Verhalten zu ändern. Es ist eine hervorragende Gelegenheit, die Boy Scout Rule anzuwenden und den Code sauberer und effizienter zu gestalten.
Herausforderungen und Lösungen
Definition von „Sauber“
Ein häufiges Problem bei der Anwendung der Boy Scout Rule ist die fehlende Klarheit darüber, was „sauberer“ oder „besser“ bedeutet. Hier ist es wichtig, dass das Team gemeinsame Standards und Best Practices festlegt.
Zeitmanagement
Es kann schwierig sein, die Zeit für die Anwendung der Boy Scout Rule zu finden, insbesondere in einem hektischen Entwicklungszyklus. Die Lösung besteht darin, kleine, inkrementelle Verbesserungen vorzunehmen, die im Laufe der Zeit addiert werden.
FAQ
Was ist die Boy Scout Rule?
Die Boy Scout Rule besagt, dass man den Code immer ein wenig besser hinterlassen sollte, als man ihn vorgefunden hat.
Wie kann ich die Boy Scout Rule in meinem Team implementieren?
Beginnen Sie mit Code Reviews und Refactoring als Möglichkeiten, die Boy Scout Rule anzuwenden. Stellen Sie sicher, dass das Team gemeinsame Standards für „sauberen Code“ hat.
Ist die Boy Scout Rule immer anwendbar?
Es gibt Situationen, in denen die Anwendung der Boy Scout Rule nicht praktikabel ist. In solchen Fällen ist es wichtig, das Risiko gegen den Nutzen abzuwägen.
Schlussfolgerung
Die Boy Scout Rule ist ein mächtiges Prinzip, das zur Verbesserung der Code-Qualität und der Teamdynamik beitragen kann. Für Intermediate Developer, die sich zu Senior Developer weiterentwickeln möchten, bietet die Anwendung dieser Regel eine hervorragende Gelegenheit, Führungsqualitäten zu demonstrieren und einen positiven Einfluss auf das Projekt zu haben.
Git ist ein Versionierung Werkzeug, mit solch einem Werkzeug ist es möglich, Versionen von Dateien zu erstellen und in einer Datenbank zu hinterlegen. Praktisches Beispiel: Du hast keine Ordner mehr mit den Namen V1, V2 usw., mit Git ist es möglich in einem Ordner mehrere Versionen von einer Datei zu speichern und zu verwalten. Git ist nicht nur für Softwareentwickler geeignet, sondern auch für Designer, da mit Git auch Bilder gut verwaltet werden können. Du bekommst eine History für deine Dateien und kannst auch nach mehreren Änderungen die Dateien wieder auf den alten Stand setzen.
Arbeiten mit anderen
Des weiteren gibt es ein weiteren großen Vorteil bei Git, das Arbeiten mit anderen wird viel einfacher. Es ist möglich einen Git Server zu erstellen, auf diesen Server werden dann die Änderungen hochgeladen und jeder (der Zugriffsrechte hat) kann sich die aktuelle Änderung runterladen. Das charmante an der Sache ist, dass nicht jedesmal das komplette Projekt runtergeladen werden muss, sondern nur die Änderung wird runtergeladen. Des weiteren wird der Git Server auf den lokalen Maschienen von den Designern und Programmieren gespiegelt. Das hat den Vorteil, dass bei einem Serverausfall, jeder weiter arbeiten kann. Falls der Git Server ein Festplattenfehler hat, sind die Daten auch nicht weg, da ja jeder ein Backup von diesem Server bei sich hat und aus diesem Backup wieder ein neuer Server erstellt werden kann.
Wie GIT Dateien speichert
Wenn du eine neue Version von dem Quellcode hast und den Code dann auf Git ablegst, wird nicht jedes mal der komplette Code gespeichert. Es wird nur die geänderte Datei gespeichert und auf die nicht geänderten Dateien wird in der neusten Version deines Quellcodes nur gezeigt. Sprich es werden Snapshots von denen Quellcode erstellt und diese ergeben dann die aktuelle Version.
die 3 Datei Status
Jetzt kommt ein wichtiger Part, diesen solltest du dir einprägen! Bei Git gibt es 3 Status, modified , staged, committed. Modified ist eine Datei, wenn sie bearbeitet wurde aber noch nicht in der Datenbank hinterlegt ist. Staged ist eine Datei, wenn sie als fertig markiert wurde und in den Commit rein kann. Committed ist eine Datei, wenn sie lokal in der Datenbank abgelegt wurde. Das bedeutet, du bearbeitest eine Datei, dann ist sie modified. Danach markierst du diese Datei und sie ist staged. Dann erstellst du ein commit mit allen staged Dateien und diese rutschen dann in die Datenbank.
Video Tutorial
SSH Einrichten
In disem Tutorial werde ich nur mit der Konsole arbeiten, sprich du brauchst erstmal die Git Bash. Auf die Installation gehe ich nicht weiter ein, da es hier sehr gut erklärt wird: https://git-scm.com/downloads.Um zu testen ob Git richtig installiert wurde, öffnest du Git Bash und gibst folgenden Befehl ein:
git --version
Bei mir kommt dann folgende Meldung:
git version 2.13.0.windows.1
Es ist kein Problem wenn du eine höhere Version hast, da die Git Entwickler auf Abwärtskompatibilität achten.
Es ist wichtig Git mitzuteilen wer man ist, da dies bei den Commits mitgespeichert wird. Dies hat den Vorteil, dass im Verlauf der Programmierer angezeigt wird und dadurch der passende Ansprechpartner für Änderungen am Code zur Verfügung steht. Um das zu machen, in der Konsole folgende Befehle eingeben:
Jetzt brauchst du noch ein Server, zum testen und ausprobieren, ich empfehle dir GitHub. Sicherheit geht vor! Deswegen sichern wir die Kommunikation mit GitHub erstmal ab. Dafür brauchst du ein rsa Schlüssel, den kannst du in der Konsole generieren.
Jetzt musst du ein Passwort eingeben, mit diesem schaltest du später immer dein privaten Schlüssel frei, also gut merken. Jetzt sollte der Schlüssel generiert worden sein, schaue im .ssh Ordner nach, ob dort 2 Schlüssel (id_rsa_github und id_rsa_github.pub) liegen
.ssh Config anlegen
Damit dein Rechner auch weiss, welcher Key verwendet werden soll, kannst du ein Config Datei anlegen mit einem Host. ~/.ssh/config:
Host github.com
IdentityFile ~/.ssh/id_rsa_github
Verbindung aufbauen
Bei mir wird der id_rsa_github.pub als Libre Office Dokument angezeigt da die Endung dort verwendet wird. Jetzt öffnest du id_rsa_github.pub mit dem Texteditor und kopierst den kompletten Inhalt. Jetzt gehst du auf https://github.com/settings/keys und trägst dort unter „new SSH Key“ deinen Schlüssel ein. Um zu testen ob der Schlüssel funktioniert, gibst du in der Konsole folgendes ein:
ssh -T git@github.com
„Are you sure you want to continue connecting (yes/no)?“ mit yes bestätigen und dein Passwort eingeben. Danach sollte „Hi [USERNAME]! You’ve successfully authenticated, but GitHub does not provide shell access.“ kommen und auf der Github Seite https://github.com/settings/keys ist das Schlüssel Symbol von schwarz auf grün geändert. FERTIG! Du hast dein Git und Github erfolgreich konfiguriert.
die Git Basics (init, status, add und commit)
Zuerst wollen wir ein Projekt anlegen
git init
Git speichert Projekte in Repositorys, übersetzt heißt das Lager, Depot oder Quelle. Es gibt 2 Varianten eine Repository zu erhalten:
clonen einer existierenden Repository
eine lokale Repository erstellen
Jetzt erkläre ich erstmal wie du eine lokale Repository erstellst und später wie du eine existierende clonst.
initialisieren einer lokalen Repository
Öffne deine Konsole und steuer mit cd dein Zielordner an, Beispiel:
cd Desktop\Projekte\boolie
Jetzt brauchst du noch ein Unterordner, den erstellst du mit mkdir:
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git init
Initialized empty Git repository in C:/Users/Marc/Desktop/Projekte/boolie/gittut/.git/
Datei anlegen und git status
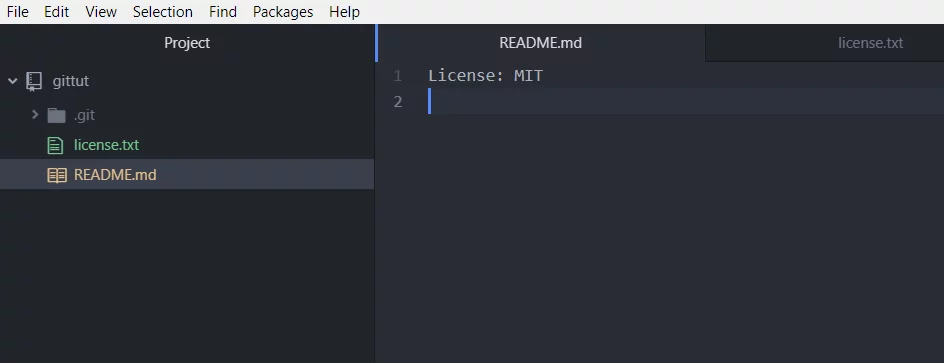
Jetzt wurde die Datenbank erstellt, sie liegt im Ordner „.git“. Dort werden jetzt deine Snapshots gespeichert. Jetzt öffne deinen bevorzugten Editor, in meinem Fall ist das Atom, und erstelle eine Datei namens README.md. Schreibe noch nichts rein erstmal nur erstellen und in den Ordner speichern. In der Konsole gibst du jetzt den Git Status befehl ein:
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Initial commit
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.md
nothing added to commit but untracked files present (use "git add" to track)
git add
Jetzt wird die README.md angezeigt, eine „untracked“ Datei, das bedeutet das Git diese Datei ignoriert und sie nicht in die Repository speichert. Das soll jetzt geändert werden, mit dem add Befehl kannst du die Datei in den staged Status versetzen.
git add README.md
git commit
Jetzt muss die README.md Datei noch in die Datenbank eingetragen werden, da ja mit staged nur eine Markierung gesetzt wurde. Um die Datei jetzt in die Datenbank zu schieben muss ein commit gemacht werden:
git commit -m "README erstellt"
Jetzt ist die Datei in der Datenbank. Das -m steht für message, sprich ein Kommentar in dem stehen sollte was geändert würde. Später kann man dann im Verlauf nachschauen, was für Änderungen am Projekt vorgenommen wurde. Mit dem Befehl log kannst du dir die Änderungen an der Repository anschauen.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git log
commit 3612a834ae48596e0cdf697a82c823a037b90efa (HEAD -> master)
Author: Marc <borkowskiberlin@gmail.com>
Date: Sat Jul 28 10:35:41 2018 +0200
README erstellt
mehrere Dateien ändern
Um diesen Prozess einzuprägen, werden wir jetzt mehrere Dateien in die Datenbank eintragen. Erstelle in deinem Editor die Datei license.txt und bearbeite die README.md, trage einfach ein Hinweis auf die Lizenz ein.
Nun schaue dir die Änderungen in Git, mit dem Befehl status an.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
Untracked files:
(use "git add <file>..." to include in what will be committed)
license.txt
no changes added to commit (use "git add" and/or "git commit -a")
Wie du siehst, werden beide Dateien angezeigt. Die README.md als modified und die license.txt als untracked. Setze beide Dateien jetzt in den staged Modus. Wieder mit dem Befehl add. Danach schaue dir die Änderungen wieder mit status an.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git add README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git add license.txt
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: README.md
new file: license.txt
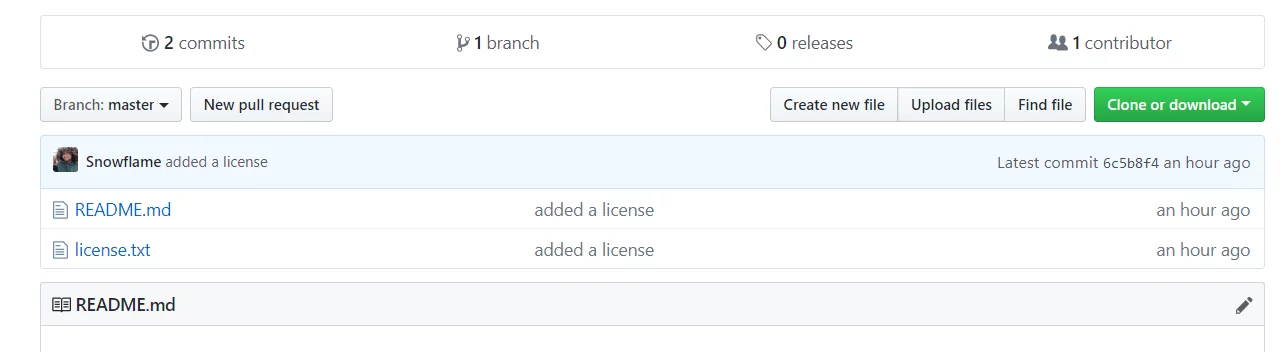
Gut, beide Dateien sind im staged Modus, jetzt der commit. Wieder mit dem Befehl commit -m „added a license“.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git commit -m "added a license"
[master 6c5b8f4] added a license
2 files changed, 1 insertion(+)
create mode 100644 license.txt
Repository auf Github schieben mit git push
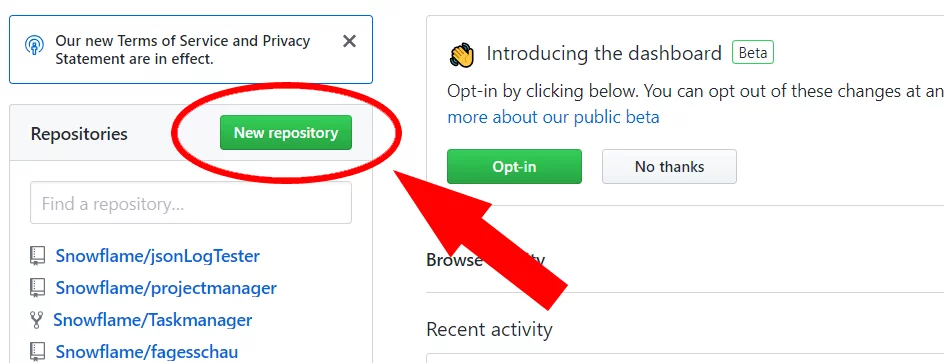
Repository erstellen
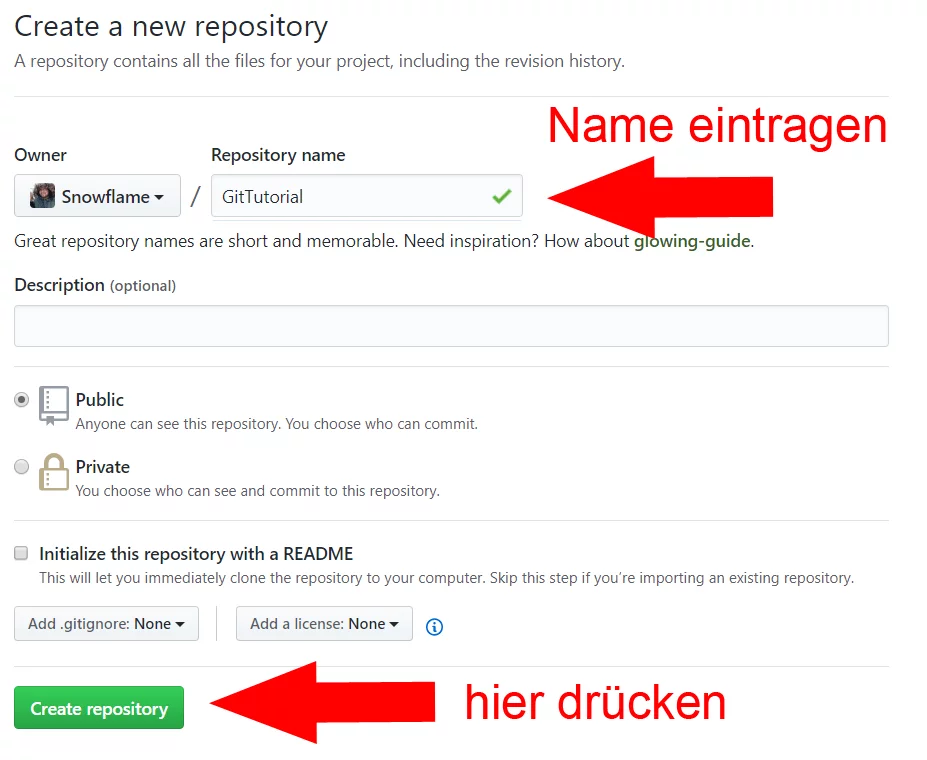
Öffne github.com, und klicke auf „New Repository“.
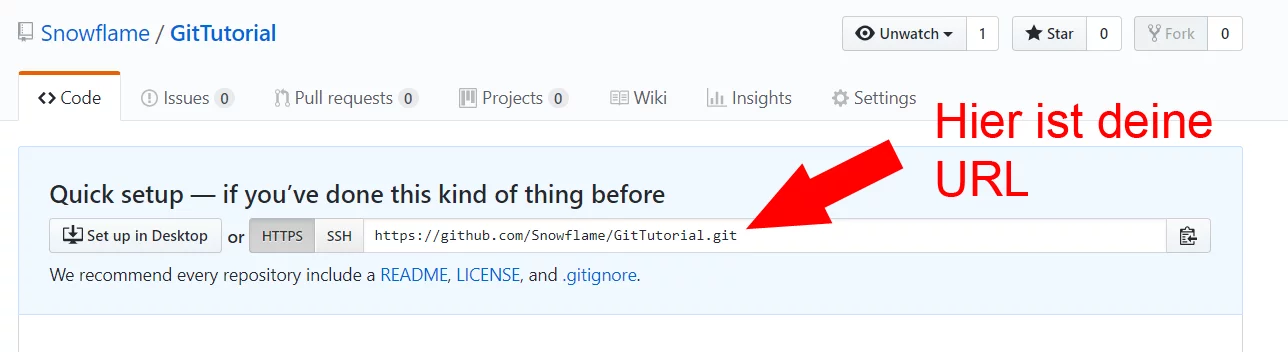
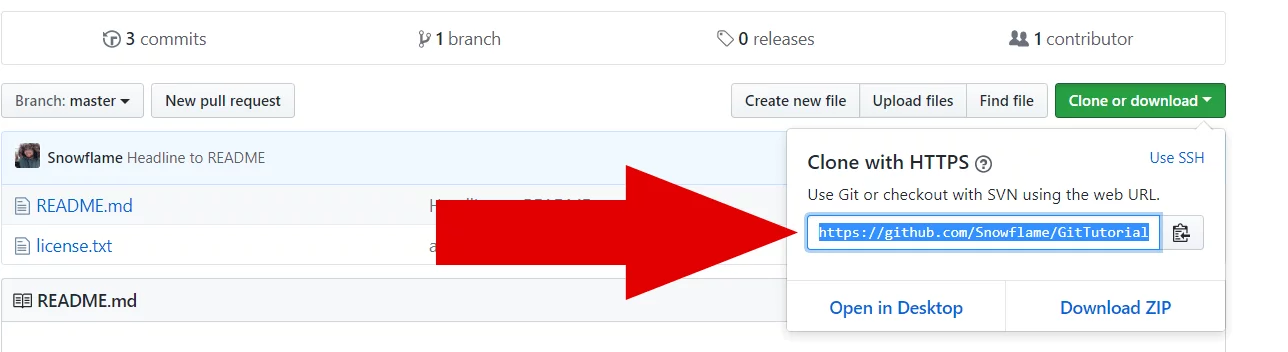
Jetzt hast du eine Repository auf einem Server. Nun werden wir die lokal erstellte Repository auf den Server schieben. Wechsel wieder in die Konsole und setze, mit dem Befehl „remote add origin“, die URL für deine lokale Repository.
Jetzt haben wir der lokalen Repository gesagt, dass es ein Server für dich gibt und du den unter der Adresse „https://github.com/Snowflame/GitTutorial.git“ findest. Jetzt müssen noch die Dateien hochgeladen werde, mit dem Befehl „push“, kannst du Dateien auf den Server schieben.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git push -u origin master
Counting objects: 6, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (6/6), 481 bytes | 0 bytes/s, done.
Total 6 (delta 0), reused 0 (delta 0)
To https://github.com/Snowflame/GitTutorial.git
* [new branch] master -> master
Branch master set up to track remote branch master from origin.
Wenn du jetzt wieder die GitHub Seite öffnest, siehst du, dass deine Dateien auf dem Server liegen.
Dateien auf den Server pushen
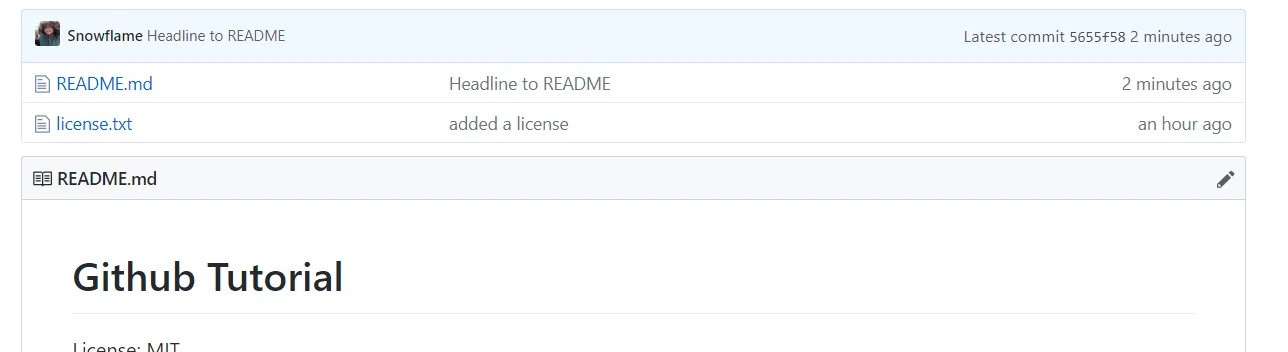
Jetzt bearbeiten wir die README.md und schieben die Änderungen auf den Server. Zuerst die Änderung, in deinem Editor, die README.md Datei bearbeiten, schreibe z.B. GitHub Tutorial, als Überschrift, rein. Wenn du dein Text schön machen willst, kannst du Markdown verwenden, hier ein schönes Markdown Tutorial. Nachdem du jetzt deine RADME.md bearbeitet hast, musst du diese auf den Server schieben. Zuerst status, dann add, dann commit und push.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git add README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git commit -m "Headline to README"
[master 5655f58] Headline to README
1 file changed, 1 insertion(+)
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git push
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 320 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/Snowflame/GitTutorial.git
6c5b8f4..5655f58 master -> master
Fertig du hast die Änderungen auf den Server geladen.
Passwort speichern
Wenn du nicht immer dein Passwort eingeben möchtest, trage eine remote URL ein.
Wenn du jetzt auf einem Anderen Computer deine Dateien vom Server laden möchtest, musst du zuerst deine Repository clonen. Wechsel zuerst in ein anderes Verzeichnes. Mit „cd ..“ wechselst du in das dadrüber liegende Verzeichnis. Dann erstellst du wieder ein Ordner mit „mkdir“, schreibe einfach eine 2 hinter den Namen und wechsle in den Ordner.
Nun clonst du die Repository von Github auf dein lokalen Rechner. Gebe in die Konsole „git clone RepositoryURL“ ein, die URL findest du auf der GitHub Seite.
Jetzt musst du auch in deinem Editor den Ordner wechseln, achte darauf, das du nicht das Oberverzeichnis auswählst, sondern die Repository. Änder jetzt die README.md und lade sie auf den Server hoch.
C:\Users\Marc\Desktop\Projekte\boolie\gittut2\GitTutorial>git add README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut2\GitTutorial>git commit -m "new line of nothing"
[master 412ffc4] new line of nothing
1 file changed, 1 insertion(+)
C:\Users\Marc\Desktop\Projekte\boolie\gittut2\GitTutorial>git push
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 336 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/Snowflame/GitTutorial.git
5655f58..412ffc4 master -> master
Jetzt wechsel wieder mit „cd“ in den orginalen Ordner und lade dir die Dateien mit pull runter.
C:\Users\Marc\Desktop\Projekte\boolie\gittut2\GitTutorial>cd ../../
C:\Users\Marc\Desktop\Projekte\boolie>cd gittut
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working tree clean
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git pull
remote: Counting objects: 3, done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 3 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), done.
From https://github.com/Snowflame/GitTutorial
5655f58..412ffc4 master -> origin/master
Updating 5655f58..412ffc4
Fast-forward
README.md | 1 +
1 file changed, 1 insertion(+)
Fertig, deine beiden Ordner sind jetzt identisch. Wenn du jetzt 2 Computer hättest, könntest du über Git deine Daten immer synchronisieren.
Dateien aus der Datenbank ausschließen
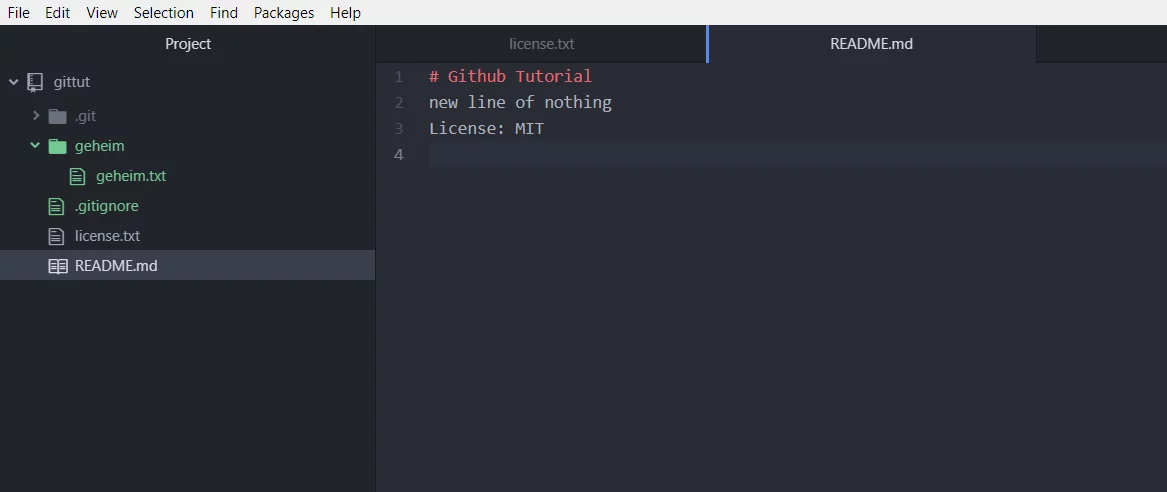
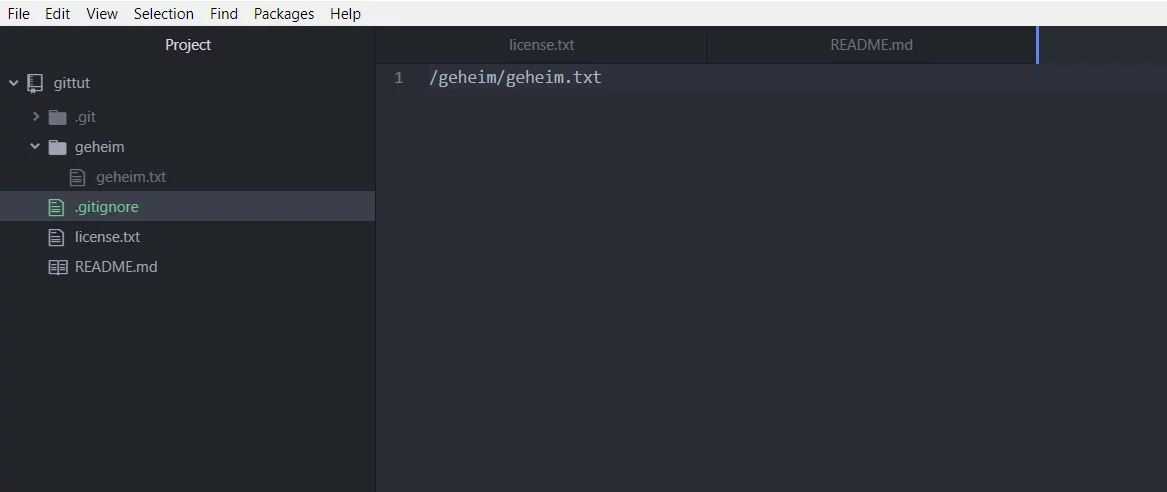
Um eine Datei dauerhaft aus GIT auszuschließen, musst du eine „.gitignore“ Datei anlegen und den Dateipfad dort eintragen. Öffne deinen Editor und lege 2 Dateien an. Zum einen die Datei „.gitignore“ und zum anderen eine Datei die du ausschließen möchtest.
In der „.gitignore“ Datei „/geheim/geheim.txt“ eintragen, um die Datei geheim.txt von der Datenbank auszuschließen.
[inline_infobox]Mit * kannst du einen ganzen Ordner ausschließen, schreibe z.B. „/geheim/*“ um alle Dateien im Ordner geheim auszuschließen. Damit ist es auch möglich bestimmte Dateiendungen aus der Datenbank auszuschließen z.B. „*.log“[/inline_infobox]
Wenn du jetzt „git status“ in deine Konsole eingibst, siehst du, dass die geheim Dateien nicht angezeigt werden und somit von Git ignoriert werden.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git add .
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: .gitignore
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git commit -m "ignoreing secret Files"
[master 252281b] ignoreing secret Files
1 file changed, 1 insertion(+)
create mode 100644 .gitignore
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git push
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 337 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/Snowflame/GitTutorial
.git
412ffc4..252281b master -> master
Datei Änderungen rückgängig machen
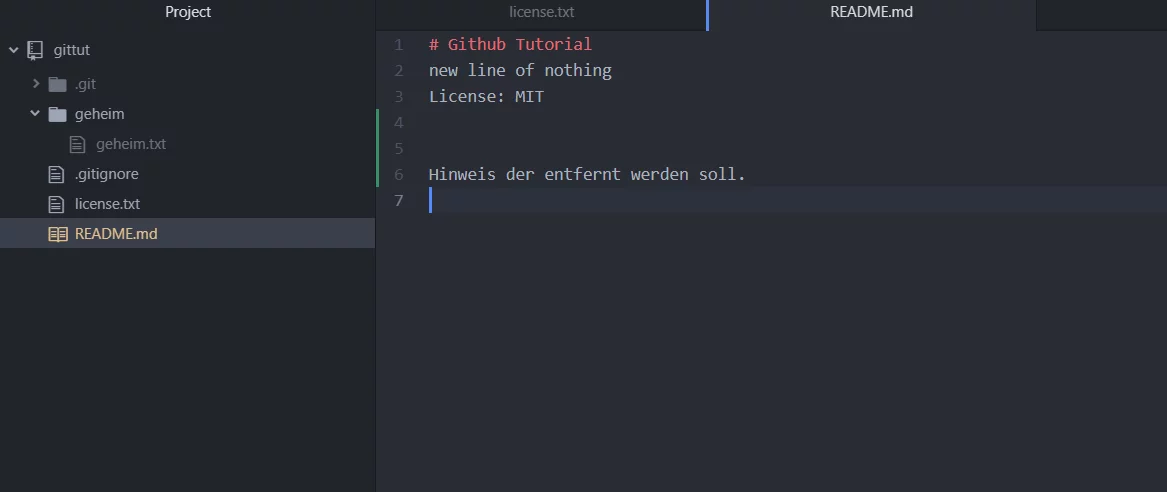
Mit dem „checkout“ Befehl lassen sich Dateien wieder auf den Uhrsprung zurück setzen. Ändere die Datei die Datei README.md, trage eine Textstelle ein. Jetzt gibst du in der Konsole „git checkout README.md“ ein, danach wird die Änderung rückgängig gemacht und die Datei ist wieder auf dem Stand des letzten pulls.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git checkout README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working tree clean
[inline_infobox]Wenn du eine Dateiänderung mit „checkout“ rückgängig machst, ist die Änderung weg, sei also vorsichtig![/inline_infobox]
Staged Markierung entfernen
Falls du schon eine Datei mit „git add“ markiert hast, aber diese doch nicht in den Commit soll, kannst du die Datei mit „git reset DATEI“ wieder aus dem staged Modus herausholen. Falls du die Datei bearbeitest und speicherst, wird die Datei automatisch aus dem staged genommen.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git add README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git reset README.md
Unstaged changes after reset:
M README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
Stash
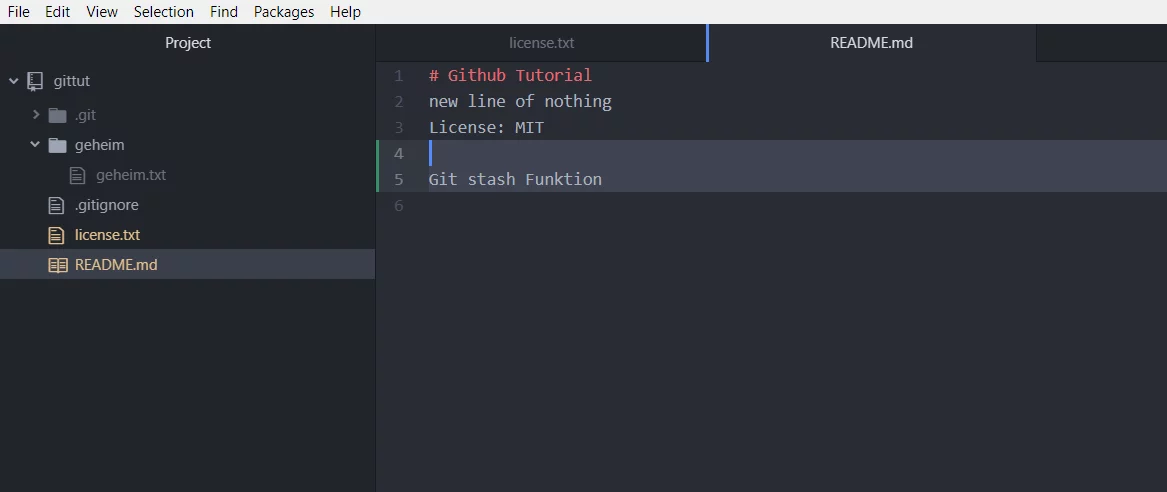
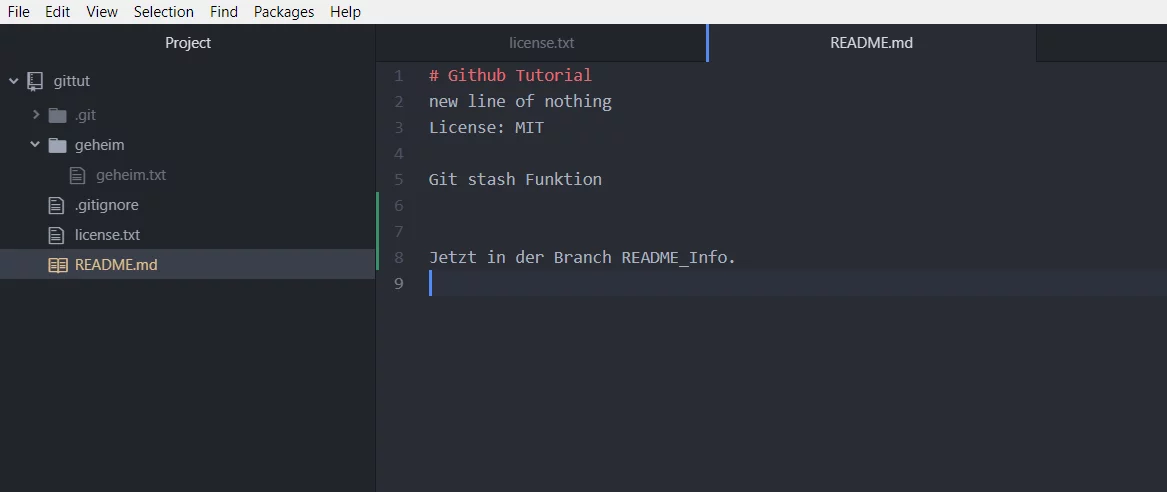
Der Stash ist eine Art Zwischenablage, du kannst deine Änderungen in den Stash legen und z.B. ein pull machen. Nach dem pull machst du ein apply und deine Änderungen sind wieder da. Schreibe eine Zeile in die README.md.
Jetzt gibst du in der Konsole „git stash“ ein.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git stash
Saved working directory and index state WIP on master: 252281b ignoreing secret Files
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working tree clean
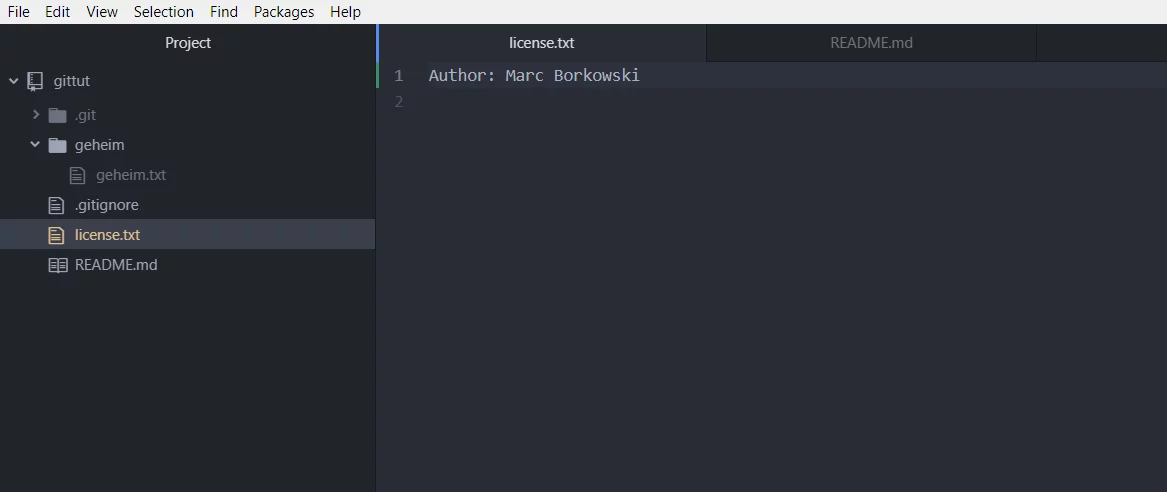
Bearbeite jetzt die license.txt, schreibe z.B. deinen Namen rein.
[inline_infobox]Um es einfach zu halten, bearbeite nicht die README.md, da sonst Probleme beim zusammenfügen der Dateien kommen wird.Dieses Theme kommt erst später.[/inline_infobox]
Jetzt führe den Befehl „git stash apply“ in der Konsole aus.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: license.txt
no changes added to commit (use "git add" and/or "git commit -a")
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git stash apply
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
modified: license.txt
no changes added to commit (use "git add" and/or "git commit -a")
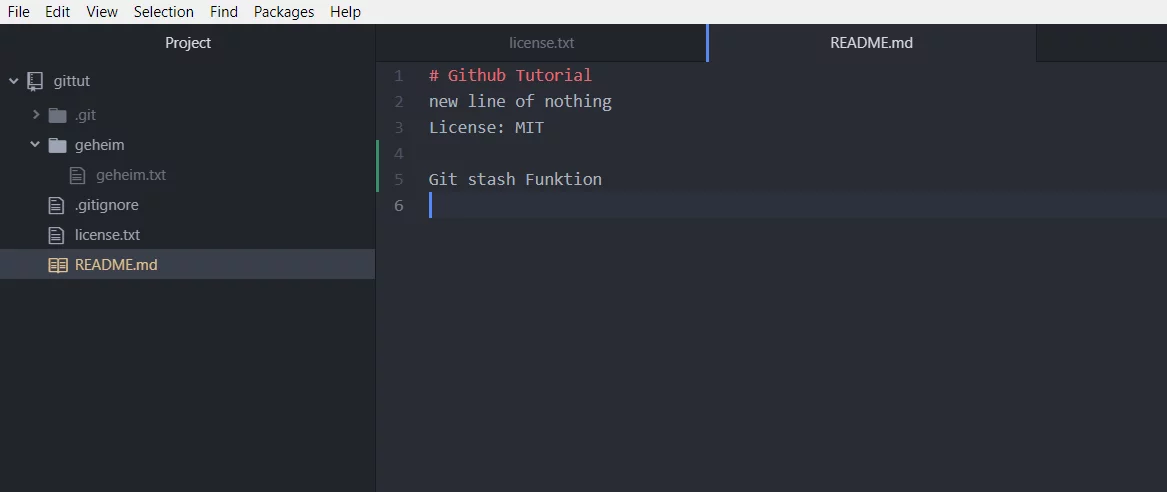
Jetzt ist die Änderung in der REAME.md wieder da!
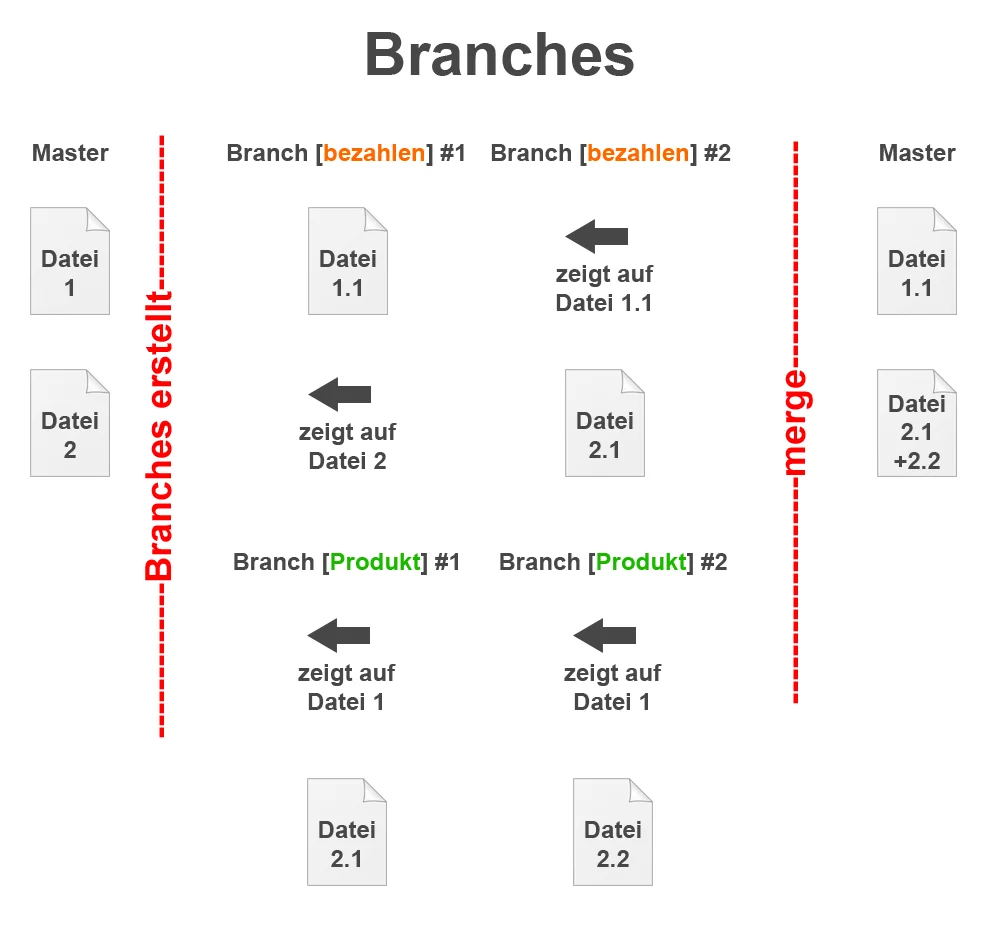
Branches
Ein Branch ist eine Sammlung von Commits, die wiederum eine neue Funktion in deiner App darstellen. Sprich jede neue Funktion in deiner App sollte eine eigene Branch besitzen. Wenn Entwickler 1 an der Branch „bezahl Funktion“ arbeitet und Entwickler 2 an „Produktauswahl“, kommen die beiden sich nicht in die Quere, da die beiden in unterschiedlichen Branches arbeiten. Später werden beide Branches dann merged und ergeben ein Paket aus neuen Funktionen für die App.
Um eine Branch zu erstellen musst du „checkout -b [NAME]“ in die Konsole eingeben. Mit dem Befehl erstellst du die Branch und wechselst gleich in die Branch. Mit dem Befehl „git branch“ kannst du dir alle Branches anzeigen lassen.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git checkout -b "README_Info"
Switched to a new branch 'README_Info'
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git branch
* README_Info
master
Wenn du jetzt in der Brnach README_Info arbeitest, werden keine Änderungen im master vorgenommen. Ändere jetzt in der REAME.md wieder eine Zeile bzw. füge eine neue Zeile ein.
Schiebe jetzt deine Branch auf den Server. Aber diesmal musst du bei deinem push ein Upstream setzen. „git push –set-upstream origin README_Info“ sagt dem Server eine neue Branch wurde erstellt und füge diese auf dem Server hinzu.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git status
On branch README_Info
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
no changes added to commit (use "git add" and/or "git commit -a")
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git add README.md
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git commit -m "new working Branch"
[README_Info 4ceb2aa] new working Branch
1 file changed, 3 insertions(+)
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git push --set-upstream origin README_Info
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 416 bytes | 0 bytes/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To https://github.com/Snowflame/GitTutorial.git
* [new branch] README_Info -> README_Info
Branch README_Info set up to track remote branch README_Info from origin.
Jetzt zeigt GitHub auch die Branch an, öffne deine Branch und klicke auf „branches“.
Du kannst mit dem „git checkout [BRANCHNAME]“ Befehl zwischen den Branches wechseln. Wechsel jetzt zurück auf den Master Branch.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git branch
* README_Info
master
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git checkout master
Switched to branch 'master'
Your branch is up-to-date with 'origin/master'.
C:\Users\Marc\Desktop\Projekte\boolie\gittut>git branch
README_Info
* master
Jetzt siehst du in deinem Editor, dass die Änderungen weg sind. Aber die Änderungen sind nicht weg, die liegen nur in der anderen Branch.
Branches mergen
Ein merge ist eine Zusammenfügung von 2 Branches, dabei wird der angegebene Branch in den aktuellen Branch eingefügt. Bei Git machst du das mit dem Befehl „git merge [BRANCH]“. Wechsle also in den Master Brnach und merge README_Info. Der Befehl sieht dann folgendermaßen aus: „git merge README_Info“.
Die beiden Elemente mit der Klasse Content erhalten den Color Wert.
.box + .content
Das Element mit der Klasse Content, muss das nächste anliegende Element von Box sein. Es darf dabei nicht von einem anderem Element unterbrochen werden.
.box + .content {
color: #009ee0;
}
<divclass="box"></div><divclass="content"></div>
Das anliegende Div-Elemnt mit der klasse Content erhält den Wert.
<divclass="teaser"><h4>Title</h4><p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.</p></div><divclass="teaser"><divclass="image">
225 x 225
</div><h4>Title</h4><p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.</p></div><divclass="teaser"><divclass="imagebig">
250 x 250
</div><h4>Title</h4><p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.</p></div>
Title
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.
225 x 225
Title
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.
250 x 250
Title
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua.
Wenn das Element die Klassen Box und Content hat, bekommt es den Farbwert zugewiesen. Beim Hover-Event wird der Farbwert überschrieben.
ES6 ist die Abkürzung für ECMAScript 6, ES6 ist der Standard für die Ausführung von JavaScript in aktuellen und kommenden Browsern und Servern. ES6 wurde 2015 entwickelt und hat neue Arbeitsweisen in Java Script implementiert. Alle gänigen Browser/NodeJs Server unterstützen ES6. In diesem Artikel findest du eine Übersicht von allen neuen Arbeitsweisen.
ES6 bringt 2 neue Datentypen mit, einmal let und zum anderen const.
let
Der Datentype let ist für Variablen, die nur im aktuellen Block verarbeitet werden sollen. Es ist zu beachten, dass let in einem verschachtelten Block auch verfügbar ist, da sich ja der verschachtelte Block auch im aktuellen Block befindet. Kurz zur Klärung, ein Block ist z.B. eine if Bedingung, eine Funktion oder eine Schleife.
if(true){
let a = 1;
console.log(a);
}
console.log(a);
1
Uncaught ReferenceError: a is not defined
Zum vergleich dazu ein Beispiel mit var:
if(true){
var a = 1;
console.log(a);
}
console.log(a);
1
1
Let überschreibt nicht die Variablen die im Block dadrüber liegen. Sprich du kannst eine Variable mit var deklarieren und den gleichen Variablennamen, mit einer let deklaration, in einer if Bedingung benutzen.
var a = 0;
console.log(a);
if(true){
let a = 1;
console.log(a);
}
console.log(a);
0
1
0
Des weiteren ist zu beachten, das z.B. in einer For Schleife der Kopf mit zum Block gehört.
let a = 10;
for(let a = 5; a > 0; a--){
console.log(a);
}
console.log(a);
5
4
3
2
1
10
const
Const steht für Konstante, eine Konstante darf nur einmal definiert werden und danach nicht mehr verändert werden, da sonst ein Fehler zurückgegeben wird. Es ist zu beachten, dass bei const immer der Name von der Konstante groß geschrieben wird.
const CONFIG_CONNECTION_IP = "127.0.0.1";
Arrow Funktionen
Vorab erstmal zeige ich dir die „alten“ Varianten Funktionen zu definieren.
Diese Definitionen sollten dir bekannt sein. Mit der Arrow Funktion kommt eine dritte Möglichkeit hinzu.
var newConsole = () => {
console.log("new World");
}
newConsole();
„var newConsole“ definiert den Funktionsnamen, „()“ die Parameter und „=>“ definiert den Übergang zum Funktionsbody. Einer der Vorteile bei dieser Variante ist die Möglichkeit die Funktion zu kürzen. Da wir nur ein Befehl in der Funktion haben, verhält sich das ähnlich wie mit einer if Bedingung, man kann die geschweiften Klammern weg lassen.
var newConsole = () =>console.log("new World");
newConsole();
Des weiteren kann man sich bei einer einzeiligen Funktion den return sparen.
var newConsole = () =>"new World";
console.log(newConsole());
Bei den Parametern gibt es auch eine kleine Besonderheit. Wenn du mehrere Parameter hast, schreibst du diese einfach mit einem Kommer getrent in die Klammern „= (parm1,parm2,parm3) =>“. Falls du nur ein Parameter hast , kannst du dir die Klammern sogar sparen „= parm1 =>“. Jetzt zeige ich dir, ein praktisches Beispiel dafür indem ich eine Variable mit einem festen Wert addieren mächte.
var addToBasis = basis => basis+5;
console.log(addToBasis(5));
10
Diese Schreibweise macht sich gut bei kurzen Callback Funktionen, z.B. bei diesem Timeout.
Arrow Funktionen unterscheiden sich zu normalen Funktionen in einer riesigen Sache, es verarbeitet „this“ anders. Bei Arrow Funktionen wird das this Objekt von der aktuellen deklarationspunkt benutzt. Das wird in einer Klasse am besten sichtbar.
classTestKlasse{
constructor() {
let thisTestArrowFunc = () =>this.test();
functionTestFunktion() {
this.test();
}
thisTestArrowFunc();
TestFunktion();
}
test(){ console.log(this) };
}
let TestObjekt = new TestKlasse();
Aber die normale Funktion kann auch Vorteile haben, z.B. wenn wir einen Button haben und dieser gedrückt wird, möchte man gerne in der Funktion mit dem Buttonobjekt über this arbeiten. Dies ist mit einer Arrow Funktion kompliziert zu bewerkstelligen.
Objekterweiterungen ist das automatische verwenden von Variablen. Wenn du eine Variable mit dem Namen „name“ definierst und danach ein Objekt mit dem Feld „name“, wird die erstellte Variable automatisch in das Objekt gespeichert.
let name = "Marc";
let person = {
name,
nachname: "Borkowski"
}
console.log(person);
Jetzt kommt der große Vorteil in der Sache, dies funktioeniert auch mit Funktionen, sprich du erstellst eine Funktion (ES5) und in dieser Funktion kannst du über this auf die einzelnen Elemente zugreifen. Hierdran siehst du auch das Arrow Funktionen Nachteile haben können. Benutze Arrow Funktionen nicht immer, diese können auch Nachteile haben.
let name = "Marc";
functionsagHallo() {
return"Hallo " + this.name;
}
let person = {
name: "Max",
nachname: "Borkowski",
sagHallo
}
console.log(person.sagHallo());
"Hallo Max"
dynamisches erstellen von Objektelmenten
Es ist möglich Objektelemente über Variableninhalte zu erstellen, dazu musst du einfach den Variablenname in Eckige Klammern beim Objekt setzen.
let name = "Marc";
let NachnamenFeld = "nachname"let person = {
name: "Max",
[NachnamenFeld]: "Borkowski"
}
console.log(person);
Der Rest Operator transformirt eine Liste von Parametern in ein Array. Das hat den Vorteil, dass die Parameter dynamisch verarbeitet werden können. Der Nachteil ist, dass als Parameter immer eine Liste und kein Array übertragen werden sollte, da sonst das Array wieder in ein Array gepackt wird.
let summeArray = (...nummern) => {
console.log(nummern);
}
summeArray(1,2,3);
summeArray([1,2,3]);
[1, 2, 3]
[[1, 2, 3]]
Als praktisches Beispiel nehme ich eine Funktion die alle Parameter summieren soll, Dies ist ohne Rest Operator äußerst schwierig, da wir erst alle möglichen Parameter prüfen müssen.
let summeArray = (...nummern) => {
let summe = 0;
for(let i = 0; i < nummern.length; i++)
summe += nummern[i];
return summe;
}
console.log(summeArray(1,2,3));
Der Spread Operator ist das Gegenteil zum Rest Operator, es wandelt ein Array in eine Liste um. Dies ist ein Vorteil, wenn du zum Beispiel die max Methode verwendest, aber ein Array hast. Der Spread Operator wird diesmal beim Funktionsaufruf verwendet, nicht beim Funktionskopf.
let nummern = [1,2,3];
console.log(Math.max(nummern));
console.log(Math.max(...nummern));
Beim Spread Operator ist auch möglich noch weitere Parameter hinzuzufügen. Man kann sogar mehrere Spread Operatoren hintereinander verwenden.
let nummern = [1,2,3];
console.log(Math.max(...nummern, ...[4,5,6], 9));
9
For of Loop
For of Loop ist eine For Schleife, in der ein Array einfacher verarbeitet werden kann. Jedes Array Element wird temporär, für den einen Intervall, in eine Variable gespeichert.
let nummern = [1,2,3,4];
for(nummer of nummern) {
console.log(nummer);
}
1
2
3
4
Dies ist natürlich auch mit einer Schleife machbar, aber diese kürzere Schreibweise macht den Code leserlicher.
Templates
Erstmal möchte ich dir das nach links gedrehte Anführungszeichen vorstellen. Neben Backspace mit gehaltener Shift Taste kannst du das Zeichen tippen -> „. Mit diesem Anführungszeichen ist es möglich Strings über mehrere Zeilen zu schreiben.
let name = "Marc
du"; // geht nichtlet name = 'Marc
du'; // geht nichtlet name = `Marc
du`; // geht
Mit den nach links gedrehten Anführungszeichen, ist es möglich Variablen mit einzubetten. Das machst du mit ${variablenname}.
let name = "Marc";
let willkommen = `Herzlich
Willkommen
${name}`;
console.log(willkommen);
"Herzlich
Willkommen
Marc"
Um ${} zu schreiben ohne das eine Variable ausgegebn werden soll, kannst du die Stelle mit \ maskieren.
let name = "Marc";
let willkommen = `Herzlich
Willkommen
\${name}`;
console.log(willkommen);
"Herzlich
Willkommen
${name}"
Es ist auch möglcih in den geschweiften Klammern Code auszuführen, als Beispiel möchte ich eine Zahl ausgeben und diese in der Ausgabe immer + 1 rechnen.
let alter = 29;
let ausgabe = `Du bist ${alter + 1}`;
console.log(ausgabe);
"Du bist 30"
Destructuring Arrays
Mit Destructuring Arrays kann man Arrays auseinandernehmen bzw. einfacher mit den Werten arbeiten. Wenn du auf der linken Seite der Variablendefinition eckige Klammern schreibst, kannst du auf einzelne Elemente von einem Array zugreifen. Das klingt zwar kompliziert, aber am Code Beispiel wirst du es schnell verstehen.
let nummern = [1,2,3];
let [a,b] = nummern;
console.log(a);
console.log(b);
1
2
Es werden 2 Variablen erstellt und diesen werden die Werte von den ersten beiden Elementen des Arrays zugewiesen. Du kannst auch den Rest Operator mit einbauen falls du alle Elemente eines Arrays haben, mit der Außname vom ersten.
let nummern = [1,2,3];
let [a, ...b] = nummern;
console.log(b);
[2, 3]
Destructuring Arrays hat noch ein großen Vorteil, Variablen vertauschen, früher brauchte man noch eine dritte Variable in den man den Wert zwischen gespeichert hat. Jetzt ist dies mit dieser Technik einfacher zu lösen.
let a = 1;
let b = 2;
console.log(a);
console.log(b);
[b, a] = [a,b];
console.log(a);
console.log(b);
1
2
2
1
Destructuring Objekte
Was mit Arrays funktioniert, klappt auch mit Objekten. Nur der Unterschied ist, dass geschweifte Klammern verwendet werden, um Objektelemente aus dem Objekt zu „ziehen“.
let objekt = {
name: 'Marc',
alter: 29,
ort: 'Rostock'
}
let {name} = objekt;
console.log(name);
let {alter, ort} = objekt;
console.log(alter, ort);
"Marc"
29
"Rostock"
Des weiteren kannst du bei Objekten noch ein Alias mithinzufügen. Wenn ein ALias angegeben ist, wird der Variablenname überschrieben. Alias werden nach dem Objektnamen mit einem Doppelpunkt geschrieben.
let objekt = {
name: 'Marc',
alter: 29,
ort: 'Rostock'
}
let {ort:stadt} = objekt;
console.log(stadt);
Mit diesem Tutorial lernst du, wie du mit HTML/CSS eine responsive Navigation baust. Zum ein- und ausklappen der mobilen Navigation hast du ein Burger-Icon.
Damit auf dem Handy die Navigation gut klickbar ist, machen wir die Einträge auf volle Breite und etwas höher. Des Weiteren entfernen wir die Abstände links und rechts, da sonst die Navigation breiter als der Bildschirm ist.
Damit die Seite auch ohne JavaScript funktioniert, habe ich mich für eine unsichtbare Checkbox entschieden. Das Bürger-Icon muss noch mit einem Label umfasst werden.

 Das Verständnis der Architektur ist entscheidend, um die Komplexität moderner Softwaresysteme zu navigieren und erfolgreiche Lösungen zu liefern.
Das Verständnis der Architektur ist entscheidend, um die Komplexität moderner Softwaresysteme zu navigieren und erfolgreiche Lösungen zu liefern. Ein tiefgehender Einblick in die monolithische Softwarearchitektur, illustriert durch realitätsnahe Beispiele wie Shopify und WordPress, und stellt einen Vergleich mit modernen Mikroservice-Architekturen an.
Ein tiefgehender Einblick in die monolithische Softwarearchitektur, illustriert durch realitätsnahe Beispiele wie Shopify und WordPress, und stellt einen Vergleich mit modernen Mikroservice-Architekturen an. Entdecken Sie die Zukunft der Softwarearchitektur: Die Vereinigung von Monolith und SOA. Erfahren Sie, wie diese Fusion die Entwicklungslandschaft neu gestaltet.
Entdecken Sie die Zukunft der Softwarearchitektur: Die Vereinigung von Monolith und SOA. Erfahren Sie, wie diese Fusion die Entwicklungslandschaft neu gestaltet.



 Jetzt gibst du in der Konsole „git checkout README.md“ ein, danach wird die Änderung rückgängig gemacht und die Datei ist wieder auf dem Stand des letzten pulls.
Jetzt gibst du in der Konsole „git checkout README.md“ ein, danach wird die Änderung rückgängig gemacht und die Datei ist wieder auf dem Stand des letzten pulls.